
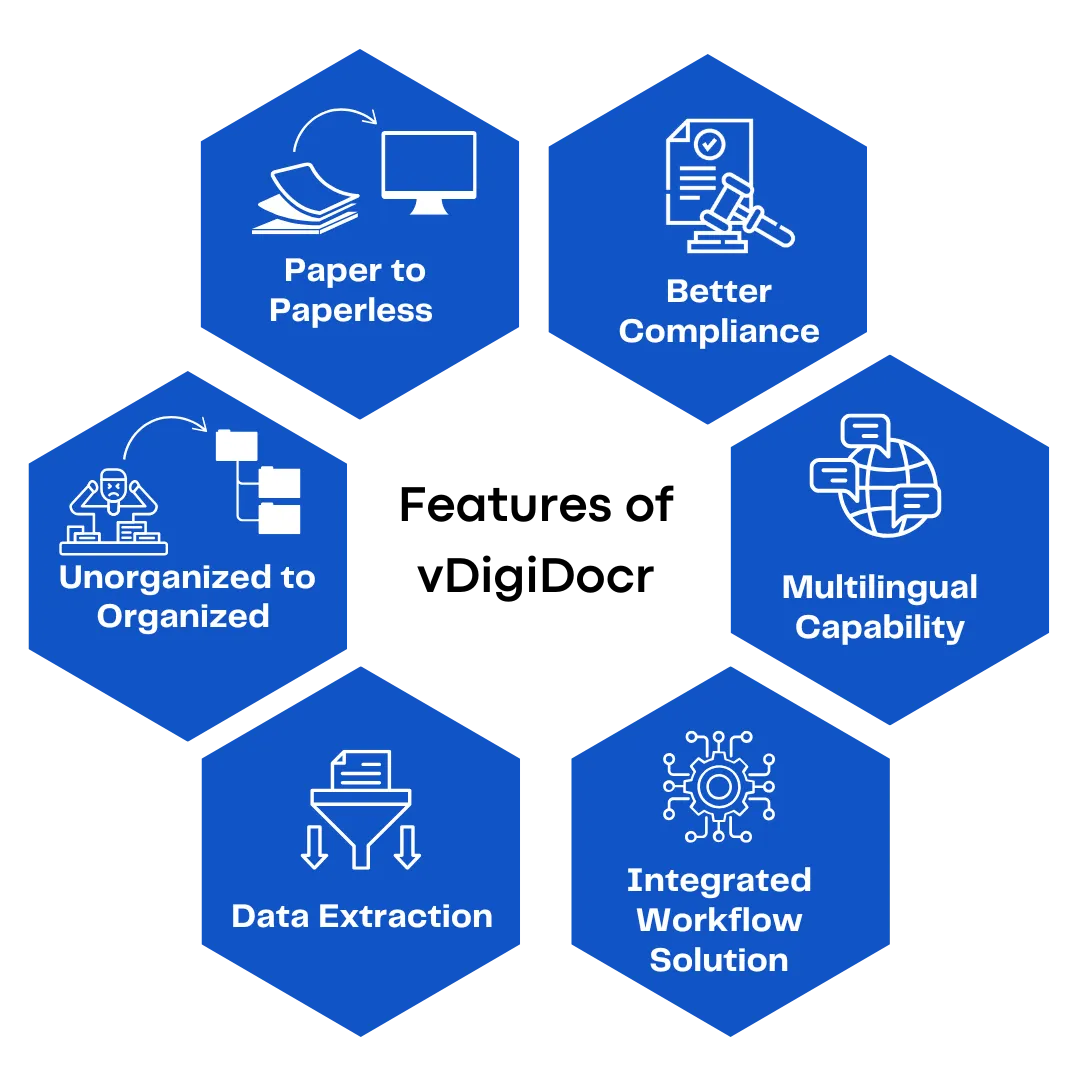
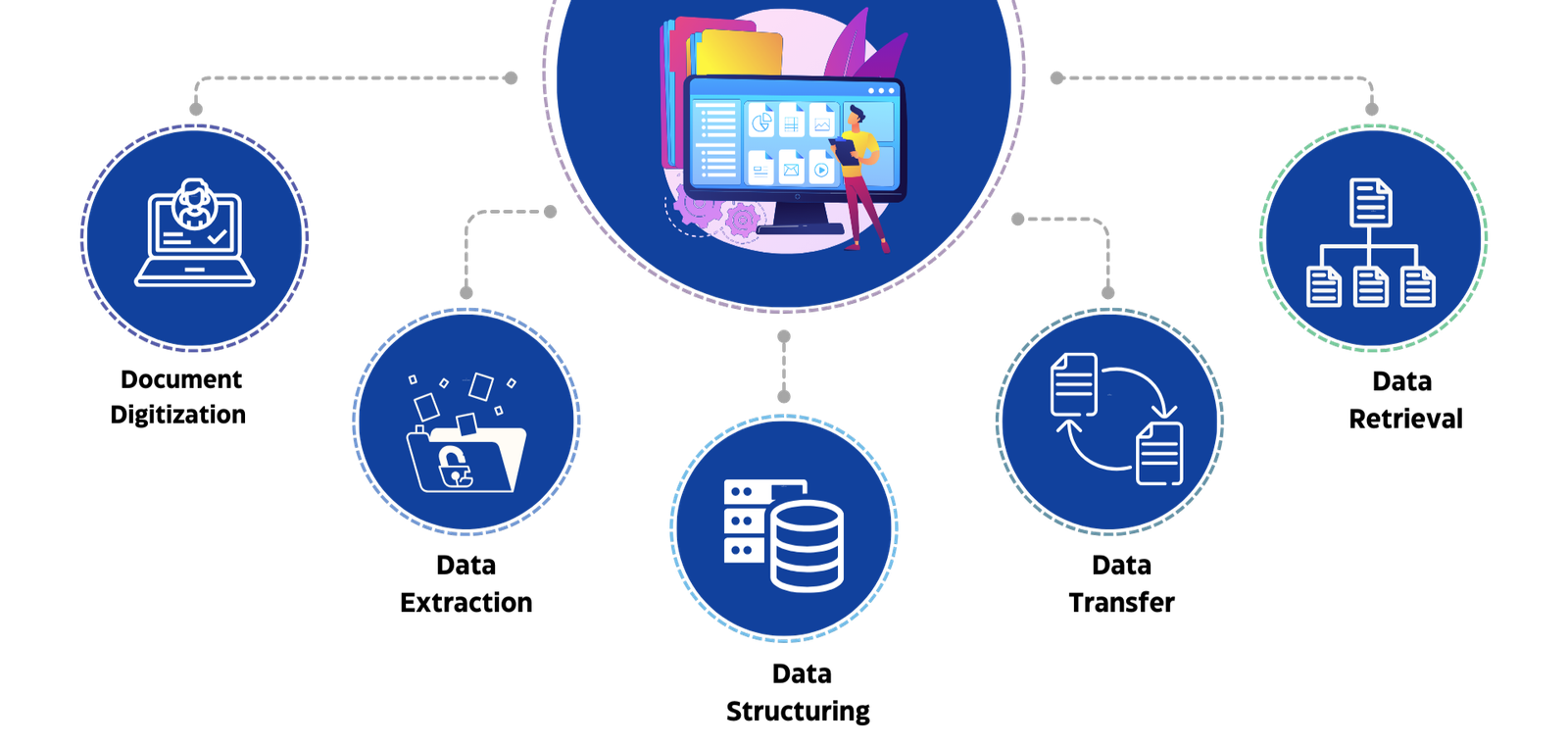
Uses Machine Learning (ML) and AI-powered OCR boasts to achieve over 95% accuracy.
Save on physical storage space by digitizing documents.
Easily locates specific documents through advanced search functionalities.
Securely store and access documents electronically.
Maintain an organized and searchable digital document archive.
Improve accessibility for visually impaired users with searchable text formats.
Ensures data confidentiality with flexible deployment options.
Process documents received through email, WhatsApp, and any other social media.
AI continuously learns and automates tasks over time.








